-
2024-03-01 PostgreSQL脱 Oracle
「脱 Oracle」 速習ガイド (PostgreSQL 11〜16 対応版)
本ガイドの目的と対象読者
本ガイドは Oracle から PostgreSQL へのデータベース移行リファレンスである。移行に要する工数の算定を容易化することを目的として、考慮すべき非互換情報をシンプルかつ具体的に整理してある。「脱 Oracle」を推進するマネジャーやリーダーのみならず、すべてのメンバーにとって必携のガイドとなることを目指した。本ガイドの情報の多くはインターネット上に公開されているが、それらが体系的、一元的に、かつ最新の PostgreSQL に対応しているものが見当たらなかった(2023年3月12日現在)。そのため、読者の便宜を図る点において本ガイドの果たす役割は大きいと考えている。
本ガイドの前提
本ガイドの内容は下記のデータベース間の移行を前提に記載してある。
| 移行元データベース | Oracle Database 11g / 12c |
|---|---|
| 移行先データベース | PostgreSQL 11 / 12 / 13 / 14 / 15 / 16 |
また、本ガイドで用いられる用語については、 Oracle と PostgreSQL とで呼称が異なる場合であっても、曖昧性を排除する目的で可能な限り一般的なものに統一してある。ただし、「関数」と「ファンクション」はデータベース用語としては同義語とみなされるが、本ガイドでは次のように使い分けている。
| 関数 | データベースの標準機能として最初から組み込まれているもの(SQL 関数)を指す。 |
|---|---|
| ファンクション | 主としてユーザーが任意で作成するもの(式を含む)を指す。また、 SQL 関数を含む広義の機能、総称としても使用する。 |
参考文献・URL
本ガイドの内容は PostgreSQL エンタープライズ・コンソーシアムが公開している調査結果(PostgreSQL 9.6 対応版)から多くの情報を得ている。 PostgreSQL 16 までのバージョン差分については、日本ヒューレット・パッカード株式会社の「篠田の虎の巻」シリーズ(著者・篠田典良氏)や SRA OSS 合同会社の「新機能検証レポート」、富士通株式会社の「PostgreSQL インサイド」などから情報を得た。これらの文献・ウェブサイトの情報は非常に有用であるため、本ガイドの内容を深掘りして学習する際には是非とも参考にされたい。
PostgreSQL エンタープライズ・コンソーシアム
日本ヒューレット・パッカード株式会社
- PostgreSQL 10 Beta1 新機能検証結果
- PostgreSQL 11 新機能検証結果
- PostgreSQL 12 新機能検証結果(GA)
- PostgreSQL 13 新機能検証結果(GA)
- PostgreSQL 14 新機能検証結果(GA)
- PostgreSQL 15 新機能検証結果(GA)
- PostgreSQL 16 新機能検証結果(GA)
SRA OSS 合同会社
- PostgreSQL 10 検証レポート
- PostgreSQL 11 検証レポート
- PostgreSQL 12 検証レポート
- PostgreSQL 13 検証レポート
- PostgreSQL 14 検証レポート
- PostgreSQL 15 検証レポート
- PostgreSQL 16 検証レポート
富士通株式会社
目次
はじめに
第1章 スキーマの移行
1.1 データ型
1.1.1 文字型
1.1.2 数値型
1.1.3 日付型
1.1.4 バイナリ型
1.2 表と索引
1.2.1 表
1.2.2 索引
1.2.3 制約
1.2.4 パーティション表
1.3 ビューとシノニム
1.3.1 ビュー
1.3.2 シノニム
1.3.3 マテリアライズド・ビュー
1.4 その他のデータベース・オブジェクト
1.4.1 トリガー
1.4.2 シーケンス
1.4.3 データベース・リンク
第2章 SQL の移行
2.1 SQL 構文
2.1.1 擬似列 ROWID / ROWNUM
2.1.2 仮想表 DUAL
2.1.3 重複行の除去 UNIQUE
2.1.4 差集合の取得 MINUS
2.1.5 DELETE 文の FROM 句
2.1.6 INSERT ALL 文
2.1.7 MERGE 文
2.1.8 別名
2.2 演算子
2.2.1 外部結合子 (+)
2.2.2 比較演算子 ^=
2.2.3 POSIX 正規表現マッチ演算子
2.3 SQL 関数
2.3.1 SQL 関数の互換性について
2.3.2 現在日時の取得と情報の精度
2.3.3 数値型における端数の丸め仕様
2.4 内部仕様の違いによる主な注意事項
2.4.1 空文字列、 NULL 値、全角スペースの扱い
2.4.2 SQL 内の除算
2.4.3 階層問い合わせにおける「深さ優先探索」
2.4.4 トランザクション
2.4.5 トランザクション分離レベル
第3章 手続き型言語とストアド・オブジェクトの移行
3.1 PL/SQL から PL/pgSQL への移行
3.1.1 PL/pgSQL について
3.1.2 基本構造とコメント
3.1.3 データ型と変数
3.1.4 繰り返しに関する命令
3.1.5 条件分岐に関する命令
3.1.6 その他の命令
3.1.7 カーソル
3.1.8 エラー・ハンドリング
3.2 ストアド・オブジェクト
3.2.1 プロシージャ
3.2.2 ファンクション
3.2.3 パッケージ
付録
A.1 SQL 関数の対応表
1.1 データ型
1.1.1 文字型
Oracle の各データ型に対応する PostgreSQL のデータ型に置換する。通常、 Oracle における文字型のサイズ指定はバイト数であるが、 PostgreSQL では文字コードによらず文字数(全角と半角の区別なし)であることに注意する。なお、日付情報を文字型や数値型で保持している場合は to_char 関数や to_date 関数による型変換を避けるため、 date 型へ移行することを推奨する。
文字型の対応
| Oracle | PostgreSQL | 備考 | ||
|---|---|---|---|---|
| CHAR | 最大 2,000 バイト |
char | 最大 1GB |
WHERE 句にて to_char 関数でリテラルを変換した場合は索引が利用されない。(to_char 関数の戻り値は text 型であり、 char 型とは互換性がないため) |
| NCHAR | ||||
| VARCHAR2 | 最大 4,000 バイト |
varchar | varchar 型と text 型は互換性があり、文字数が不定の場合は text 型を利用する選択肢もある。 | |
| NVARCHAR2 | ||||
| LONG | 2GB-1 バイト |
text | 1GB を超える場合はラージ・オブジェクトを使用するか、外部ファイルに保存する。 | |
| CLOB | 4GB-1 バイト |
|||
| NCLOB | ||||
1.1.2 数値型
Oracle の NUMBER 型に完全一致するデータ型が PostgreSQL に存在しないため、桁数と精度に応じて置換する。 PostgreSQL の numeric 型は非常に大きな数値を扱え、正確な計算が可能であることから通貨や高精度の数値を扱うのに向いている。その反面、 integer 型や bigint 型と比べて処理速度が劣るため、用途に応じて使い分けると良い。なお、 Oracle の FLOAT 型に相当するものが PostgreSQL にも存在するが、保持可能な精度が異なる点に注意する。数値型における非互換については後述の「2.3.3 数値型における端数の丸め仕様」と「2.4.2 SQL 内の除算」もあわせて参照のこと。
数値型の対応
| Oracle | PostgreSQL | ||
|---|---|---|---|
| NUMBER | 10進数38桁 | decimal | 整数部(131,072桁)、 小数部(16,383桁) ※ decimal は numeric と等価 |
| numeric | |||
| smallint | 整数(-32,768〜32,767) | ||
| integer | 整数 (-2,147,483,648〜2,147,483,647) |
||
| bigint | 整数 (-9,223,372,036,854,775,808〜 9,223,372,036,854,775,807) |
||
| real | 単精度浮動小数点数(6桁) | ||
| double precision | 倍精度浮動小数点数(15桁) | ||
| FLOAT | 浮動小数点数 (2進数126桁) |
float | 浮動小数点数(2進数53桁) ※ double precision と等価 |
| BINARY_FLOAT | 単精度浮動小数点数 | real | 単精度浮動小数点数(6桁) |
| BINARY_DOUBLE | 倍精度浮動小数点数 | double precision | 倍精度浮動小数点数(15桁) |
1.1.3 日付型
Oracle の各データ型に対応する PostgreSQL のデータ型に置換する。なお、 Oracle の DATE 型に相当するものが PostgreSQL にも存在するが、保持可能な精度が異なる点に注意する。なお、 PostgreSQL には時刻のみを保持する time 型が存在し、時刻による条件指定や集計などで利点がある。
日付型の対応
| Oracle Database | PostgreSQL | ||
|---|---|---|---|
| DATE | 日付と時刻 (秒単位) -4712/01/01〜9999/12/31 |
date | 日付のみ |
| timestamp | 日付と時刻 (時間帯なし:マイクロ秒単位) 紀元前4713年〜294276年 |
||
| TIMESTAMP | 日付と時刻 (時間帯なし:ナノ秒単位) |
||
| TIMESTAMP WITH TIMEZONE |
日付と時刻 (時間帯あり:ナノ秒単位) |
timestamp with timezone |
日付と時刻 (時間帯あり:マイクロ秒単位) 紀元前4713年〜294276年 |
| TIMESTAMP WITH LOCAL TIMEZONE |
日付と時刻 (ローカル時間帯あり:ナノ秒単位) |
||
| INTERVAL YEAR TO MONTH |
年と月 | interval | 時間間隔 (マイクロ秒単位) -178000000年〜178000000年 |
| INTERVAL DAY TO SECOND |
日付と時刻 (秒単位) |
||
1.1.4 バイナリ型
Oracle の各バイナリ型は PostgreSQL の bytea 型に置換する。ただし、 1GB を超える場合はラージ・オブジェクトを使用するか、外部ファイルに保存する。ラージ・オブジェクトを使用する際の注意点は、表の当該行の削除に連動しない(別途、メンテナンスの必要性がある)こと、ラージ・オブジェクトを含む行に対する参照や変更が、データベースに接続済みの全ユーザーから権限に関係なく可能であることである。
バイナリ型の対応
| Oracle | PostgreSQL | 備考 | ||
|---|---|---|---|---|
| RAW | 2,000 バイト |
bytea | 最大 1GB (可変長) |
1GB を超える場合はラージ・オブジェクトを使用するか、外部ファイルに保存する。 |
| LONG RAW | 2GB-1 バイト |
|||
| BLOB | 4GB-1 バイト |
|||
1.2 表と索引
1.2.1 表
データ型については前節の「1.1 データ型」を参照し、適切に置換する。 Oracle と PostgreSQL では CREATE TABLE 文を構成する各パラメータの移植性が低く、唯一、 PCTFREE に相当するものとして fillfactor が存在するのみである。なお、 PCTFREE が空き領域の割合を指定するのに対し、 fillfactor は挿入時に使用可能な領域の割合を指定する点が異なる。
表の作成例
|
-- PCTFREE が初期値(10)の場合、 fillfactor = 90 を指定(fillfactor = 100 - PCTFREE) CREATE TABLE sales(emp_id int, p_name text, sales_amount int, sales_date date) WITH(fillfactor = 90); |
fillfactor の簡易導出式
| 対象 | 初期値 | 簡易導出式 | |
|---|---|---|---|
| PCTFREE | 表 | 10 | fillfactor = fillfactor の初期値 - PCTFREE
一般的に fillfactor の下限は70程度とされる。設定値が小さすぎるとデータの格納効率が低下し、参照性能などに影響することがある。通常は fillfactor を設定せず、初期値で運用しても問題はない。 |
| 索引 | 10 | ||
| fillfactor | 表 | 100 | |
| 索引 | 90 | ||
Oracle において PCTFREE で確保した空き領域を利用するのは、サイズが大きくなる UPDATE 文を実行した場合に限られる。 PostgreSQL において UPDATE 文を実行した場合、 fillfactor = 100 でない限り、必ず確保した空き領域を利用する。
1.2.2 索引
Oracle の B-tree 索引とファンクション索引(一部に制約あり)は PostgreSQL に移行できる。それ以外の索引は B-tree 索引や GiST 索引などで代替を検討する。PCTFREE と fillfactor については前項の「1.2.1 表」を参照のこと。
索引の作成例
|
-- B-Tree 索引 CREATE INDEX idx_sales(emp_id int); |
索引の対応
| 項目 | 移行 | 備考 |
|---|---|---|
| B-tree 索引 | ○ | |
| ○ | Oracle 独自のファンクションを式に利用している場合には PostgreSQL のファンクションに置換する必要がある。また、下記の例における date_timestamp のように、参照のたびに値が変わるデータ型に対してはファンクション索引を作成できない。
CREATE INDEX index_test ********** エラー ********** |
|
| その他の索引 | × | B-tree 索引や GiST 索引などで代替を検討する。 |
1.2.3 制約
Oracle の制約は PostgreSQL に移行できる。ただし、 CHECK 制約などに Oracle 独自のファンクションを利用している場合は PostgreSQL のファンクションに置換する必要がある。なお、 Oracle では制約のチェックが DML 文の実行時に行われるのに対し、 PostgreSQL は行単位であるため、行の物理的な格納順により SQL の実行結果が異なることがある。
制約の対応
| 制約名 | オプション | Oracle | PostgreSQL | ||
|---|---|---|---|---|---|
| 列 | 表 | 列 | 表 | ||
| PRIMARY KEY | - | ○ | ○ | ○ | ○ |
| UNIQUE | - | ○ | ○ | ○ | ○ |
| NOT NULL | - | ○ | × | ○ | × |
| CHECK | - | ○ | ○ | ○ | ○ |
| DEFAULT | - | ○ | × | ○ | × |
| REFERENCES | 指定なし | ○ | ○ | ○ | ○ |
| ON DELETE CASCADE | ○ | ○ | ○ | ○ | |
制約のチェックが行単位であることに起因する非互換の例
|
SELECT * FROM tbl;
pkey | col UPDATE tbl SET pkey = pkey + 1; ERROR: duplicate key value violates unique constraint "pkey" UPDATE tbl SET pkey = pkey - 1; UPDATE 3 |
1.2.4 パーティション表
Oracle のパーティション表のうち、代表的な3つの方式(レンジ、リスト、ハッシュ)と、これらを組み合わせたコンポジット・パーティションは PostgreSQL に移行できる。
レンジ・パーティション表の作成例
|
-- 親パーティション表の作成 CREATE TABLE sales(emp_id int, p_name text, sales_amount int, sales_date date) PARTITION BY RANGE(sales_date); -- 子パーティション表の作成(FROM の下限値データは含み、 TO の上限値データは含まれない) -- デフォルト・パーティション表の作成 |
リスト・パーティション表の作成例
|
-- 親パーティション表の作成 CREATE TABLE sales_region (emp_id int, sales_amount int, branch text, region text) PARTITION BY LIST(region); -- 子パーティション表の作成 -- デフォルト・パーティション表の作成 |
ハッシュ・パーティション表の作成例
|
-- 親パーティション表の作成 CREATE TABLE emp(emp_id int, emp_name text, dep_code int) PARTITION BY HASH(emp_id); -- 子パーティション表の作成(パーティション数を3、ハッシュ値の剰余を 0, 1, 2 とする) |
REMAINDER 句には MODULUS 句よりも小さい値を指定する。パーティション数が MODULUS 句で指定した値より小さい場合、ハッシュ値の剰余に該当する表が存在しないため INSERT 文がエラーになる可能性がある。
ハッシュ・パーティション表に対する子パーティション表の追加例
|
-- トランザクションの開始(本番稼動中に実施する場合) BEGIN; -- 親パーティション表から子パーティション表をデタッチ(切り離し) -- 子パーティション表のデータをバックアップするためにリネーム -- 新しい子パーティション表の作成(分割数を6、ハッシュ値の剰余を 0, 1, 2, 3, 4, 5 とする) -- バックアップした古い子パーティション表のデータを新しい子パーティション表にリストア -- 古い子パーティション表の削除 -- トランザクションの終了 |
PostgreSQL では DDL のロールバックが可能である。
1.3 ビューとシノニム
1.3.1 ビュー
Oracle と同様に、表結合や集合関数などを含まないシンプルなビューは PostgreSQL でも更新可能ビューとなる。また、この特徴を利用してシノニムを代替できる。
ビューの作成例
|
-- ビューの作成(更新可能) CREATE VIEW emp_view AS SELECT * FROM emp; -- ビューの更新可否を確認 table_name | is_updatable |
ビュー・オプションの対応
| オプション | Oracle | PostgreSQL |
|---|---|---|
| ビュー定義 に違反する 更新の禁止 |
WITH CHECK OPTION |
WITH(check_option) |
| WITH(check_option = cascade)
元ビューの条件を制限の対象とする。 |
||
| WITH(check_option = local)
元ビューの条件を制限の対象としない。 |
1.3.2 シノニム
Oracle のシノニムに相当するものが PostgreSQL に存在しないため、下記の方法で代替する。
シノニムの対応
| 代替方法 | 説明 |
|---|---|
| 更新可能ビュー | 別スキーマの表に対して更新可能ビューを作成する。 ※ SELECT リストは全列を対象とし、WHERE 句を指定しないこと。 |
| public スキーマの活用 |
サーチパスに public スキーマを含め、表を public スキーマに配置する。 (これにより任意のユーザから透過的に参照と更新が可能となる) |
1.3.3 マテリアライズド・ビュー
PostgreSQL のマテリアライズド・ビューは Oracle と比べて機能的な制約が多いので注意する。たとえば、定期的なデータ同期のためには cron などを利用して REFRESH コマンドを実行する必要がある。また、システム要件として高速同期を満たす必要がある場合、マテリアライズド・ビューに保持する検索結果を別表として用意し、元表の最新データと同期させる仕組みをトリガーなどで実装する必要がある。
マテリアライズド・ビューの作成例
|
-- マテリアライズド・ビューの作成 CREATE MATERIALIZED VIEW emp_mview AS SELECT deptno, sum(sal) AS sal FROM emp GROUP BY deptno; -- マテリアライズド・ビューのリフレッシュ -- マテリアライズド・ビューのリフレッシュ( CONCURRENTLY オプションあり) |
CONCURRENTLY オプションを付与しない場合、リフレッシュ処理中は ACCESS EXCLUSIVE ロックが発生し、 SELECT 処理が待機する。付与した場合はロック競合が緩和され、リフレッシュ処理中の SELECT 処理が可能となる。ただし、 CONCURRENTLY オプションを付与するには対象のマテリアライズド・ビューに下記の条件を満たす UNIQUE 索引が少なくとも一つ必要である。
- ファンクション索引(式索引)でないこと(CREATE INDEX 文に SQL 関数や演算が含まれていない)
- 部分索引でないこと(CREATE INDEX 文に WHERE 句が含まれていない)
マテリアライズド・ビューの主な機能差分
| 項目 | Oracle | PostgreSQL | |
|---|---|---|---|
| アクセス方式 | 読み取り | ○ | ○ |
| 更新可能 | ○ | × | |
| リフレッシュ方式 | 自動 / 手動 | 自動 / 手動 | 手動 |
| 完全(全体) | ○ | ○ | |
| 高速(差分) | ○ | × | |
| クエリー・リライト | ○ | × | |
1.4 その他のデータベース・オブジェクト
1.4.1 トリガー
PostgreSQL のトリガーは Oracle との互換性がないため、 PL/pgSQL による置換が必要である。 PostgreSQL のトリガーは、処理部となるトリガー・ファンクションと、その処理を呼び出すためのトリガーをペアで作成する。 PL/pgSQL については「第3章 手続き型言語とストアド・オブジェクトの移行」を参照のこと。
トリガーの作成例
|
-- トリガー・ファンクションの作成 CREATE FUNCTION emp_stamp() RETURNS trigger AS $$ BEGIN -- empname と salary が与えられていることを確認 IF NEW.empname IS NULL THEN RAISE EXCEPTION 'empname cannot be null'; END IF; IF NEW.salary IS NULL THEN -- 支払い時に問題が起きないように -- いつ、誰が変更したかを記録 -- トリガーの作成 -- 更新 -- 参照 empname | salary | last_date | last_user |
トリガー契機文の対応
| トリガー契機文 | Oracle | PostgreSQL |
|---|---|---|
| INSERT | IF INSERTING THEN | IF(TG_OP = 'INSERT') THEN |
| UPDATE | IF UPDATING THEN | IF(TG_OP = 'UPDATE') THEN |
| DELETE | IF DELETING THEN | IF(TG_OP = 'DELETE') THEN |
| TRUNCATE | - | IF(TG_OP = 'TRUNCATE') THEN |
トリガーの主なオプション
| オプション | PostgreSQL |
|---|---|
| 処理単位 | ROW / STATEMENT |
| 処理タイミング | BEFORE / AFTER / INSTEAD OF |
| トリガー契機文 | INSERT / UPDATE / DELETE / TRUNCATE |
擬似レコードの修飾語
| 新旧レコード | Oracle | PostgreSQL |
|---|---|---|
| 新規 | :NEW. | NEW. |
| 既存 | :OLD. | OLD. |
1.4.2 シーケンス
Oracle と PostgreSQL とで、シーケンスの取り得る値の範囲が異なる点に注意する。シーケンスの値が PostgreSQL の制限に収まらない場合は値を初期化したり、別のシーケンスと組み合わせることを検討する。ただし、仮に毎秒1万件をカウントしたとして、値が枯渇するのに約3,000万年を要することから、通常は PostgreSQL のシーケンスの最大値が問題になることはない。
シーケンスの作成例
|
CREATE SEQUENCE seq_test1 START WITH 1 INCREMENT BY 1 MAXVALUE 100 NO MINVALUE CYCLE CACHE 20 ; |
シーケンスの最大値と最小値が取り得る範囲
| 項目 | Oracle | PostgreSQL |
|---|---|---|
| 最大値 | 9,999,999,999,999,999,999,999,999,999 | 9,223,372,036,854,775,807 |
| 最小値 | -999,999,999,999,999,999,999,999,999 | -9,223,372,036,854,775,808 |
シーケンスに対する主な操作コマンドの違い
| 項目 | Oracle | PostgreSQL |
|---|---|---|
| 次の値を取り出す | シーケンス名.nextval | nextval('シーケンス名') |
| 現在値を取り出す | シーケンス名.currval | currval('シーケンス名') |
1.4.3 データベース・リンク
Oracle のデータベース・リンクに相当するものが PostgreSQL に存在しないため、 FDW (Foreign Data Wrapper)で代替する。なお、従来からの方法として dblink が存在するが、より自然な SQL 構文が利用できる FDW を推奨する。ただし、結合(JOIN)やソート(ORDER BY, LIMIT)、集約(GROUP BY)などはリモートから取得後にローカルで実行されるため、処理速度に影響することがある。
FDW(posgres_fdw)の利用例
|
-- postgres_fdw の作成 CREATE EXTENSION postgres_fdw; -- 外部サーバの作成 -- ユーザ・マッピングの作成 -- 外部テーブルの作成 -- データの参照 id | name | manager_id |
FDW とは SQL を利用して外部データにアクセスするための PostgreSQL の拡張機能である。 PostgreSQL が公開しているライブラリを利用して Oracle などの RDBMS 、あるいは NoSQL 、CSV など、連携したいデータに合わせて独自に作成できる。これまでに多くの企業やプロジェクト、個人が各用途ごとの FDW を提供しており、120種類ほどが公開されている。
https://wiki.postgresql.org/wiki/Foreign_data_wrappers
2.1 SQL 構文
2.1.1 擬似列 ROWID / ROWNUM
Oracle の擬似列に相当するものが PostgreSQL に存在しないため、 ROWID 擬似列は主キーでの代替を検討する。 ROWNUM 擬似列については SELECT リストで行番号を取得する場合、 Window 関数の一つである row_number 関数で代替する。また、 WHERE 句で取得件数を制御する場合は LIMIT 句や FETCH 句などで代替する。
row_number 関数による代替例(SELECT リストで行番号を取得)
| Oracle | PostgreSQL |
|---|---|
|
SELECT * FROM (SELECT * FROM test ORDER BY id) WHERE ROWNUM <= 10; |
SELECT * FROM (SELECT row_number() OVER(ORDER BY id) AS rownum, id FROM test) AS t WHERE rownum <= 10; |
LIMIT 句と OFFSET 句による代替例(SQL の簡素化を重視)
| SELECT * FROM test ORDER BY id LIMIT 5 OFFSET 10; |
FETCH 句による代替例(標準 SQL への準拠を重視)
| SELECT * FROM test ORDER BY id OFFSET 10 ROWS FETCH FIRST 5 ROWS ONLY; |
2.1.2 仮想表 DUAL
Oracle では SELECT 文の FROM 句を省略できないため、実表を必要としない場合に仮想表を用いる。 PostgreSQL には仮想表が存在しないため、 SELECT 文から FROM DUAL を取り除く必要がある。
仮想表の除去例
| Oracle | PostgreSQL |
|---|---|
| SELECT current_timestamp FROM DUAL; | SELECT current_timestamp; |
2.1.3 重複行の除去 UNIQUE
Oracle 独自の UNIQUE 句は、標準 SQL の DISTINCT 句に置換する。
UNIQUE 句の置換例
| Oracle | PostgreSQL |
|---|---|
| SELECT UNIQUE * FROM tbl; | SELECT DISTINCT * FROM tbl; |
2.1.4 差集合の取得 MINUS
Oracle 独自の MINUS 句は、標準 SQL の EXCEPT 句に置換する。
MINUS 句の置換例
| Oracle | PostgreSQL |
|---|---|
|
SELECT col1, col2 FROM tbl1 MINUS SELECT col1, col2 FROM tbl2; |
SELECT col1, col2 FROM tbl1 EXCEPT SELECT col1, col2 FROM tbl2; |
2.1.5 DELETE 文の FROM 句
Oracle では DELETE 文の FROM 句を省略できるが、これは標準 SQL に準拠したものではない。 PostgreSQL では構文エラーとなるため、 FROM 句が省略されている場合は書き足す必要がある。
FROM 句の追加例
| Oracle | PostgreSQL |
|---|---|
| DELETE tbl WHERE id = 2; | DELETE FROM tbl WHERE id = 2; |
2.1.6 INSERT ALL 文
Oracle 独自の INSERT ALL 文のうち、複数の表に INSERT 文を実行する、いわゆるマルチテーブル・インサートに相当するものは PostgreSQL には存在しない。この場合は個々の表に対して INSERT 文を実行するように書き換える必要がある。ただし、単一の表に対して複数行の INSERT 文を実行する場合は標準 SQL で置換できる。
INSERT ALL 文の置換例
| Oracle | PostgreSQL |
|---|---|
|
INSERT ALL INTO tbl VALUES (1, 'one') INTO tbl VALUES (2, 'two') INTO tbl VALUES (3, 'three') SELECT * FROM DUAL; |
INSERT INTO tbl VALUES (1, 'one'), (2, 'two'), (3, 'three') ; |
2.1.7 MERGE 文
PostgreSQL 14 以前は MERGE 文に対応していないため、 INSERT ON CONFLICT 構文で置換する。 PostgreSQL 15 からは標準 SQL である MERGE 文に対応しているが、 WITH 句内や COPY 文と同時には使用できないことに注意する。
MERGE 文の置換例
| Oracle | PostgreSQL |
|---|---|
|
MERGE INTO emp_shisya s USING emp_honsya h ON (s.empno = h.empno) WHEN MATCHED THEN UPDATE SET s.ename = h.ename, s.job = h.job WHEN NOT MATCHED THEN INSERT VALUES (h.empno, h.ename, h.job) ; |
INSERT INTO emp_shisya (empno, ename, job) SELECT empno, ename, job FROM emp_honsya ON CONFLICT (empno) DO UPDATE SET ename = EXCLUDED.ename, job = EXCLUDED.job ; |
既存行が存在する場合に何もしない DO NOTHING オプションの例
|
INSERT INTO emp_shisya (empno, ename, job) SELECT empno, ename, job FROM emp_honsya ON CONFLICT (empno) DO NOTHING; |
2.1.8 別名
PostgreSQL の列に対して別名をつける場合、原則として AS 句を指定することは得策である。これにより SQL の可読性が向上したり、予約語に関する構文エラーを回避できる。また、 PostgreSQL は副問い合わせに対する別名が必須であり、省略すると構文エラーとなる。
別名の対応
| 別名の対象 | 記述方法 | Oracle | PostgreSQL |
|---|---|---|---|
| 列 | 別名なし | ○ | ○ |
| 列名 AS 別名 | ○ | ○ | |
| 列名 別名 | ○ | ○ ※ 予約後の場合はエラー |
|
| 副問い合わせ | 別名なし | ○ | × ※ 別名が必須 (PostgreSQL 16 以降、 FROM 句中については ○) |
| 副問い合わせ AS 別名 | ○ | ○ | |
| 副問い合わせ 別名 | ○ | ○ |
FROM 句中の副問い合わせ
| Oracle | PostgreSQL |
|---|---|
| SELECT * FROM (SELECT * FROM tbl); | SELECT * FROM (SELECT * FROM tbl) AS sub; |
なお、PostgreSQL 16 以降は FROM 句中の副問い合わせにおける別名が必須でなくなった。
UPDATE 文の SET 句中の別名
| Oracle | PostgreSQL |
|---|---|
| UPDATE emp AS e SET e.ename = 'XXXXX'; | UPDATE emp AS e SET ename = 'XXXXX'; |
更新対象列が別名で修飾されている場合は取り除く必要がある。
2.2 演算子
2.2.1 外部結合演算子 (+)
Oracle 独自の外部結合演算子 (+) は、標準 SQL の OUTER JOIN 構文に置換する。
外部結合演算子の置換例
| Oracle | PostgreSQL |
|---|---|
|
-- 右外部結合 SELECT * FROM foo, bar WHERE foo.id = bar.id (+); -- 左外部結合 -- 完全外部結合 |
-- 右外部結合 SELECT * FROM foo RIGHT OUTER JOIN bar ON foo.id = bar.id; -- 左外部結合 -- 完全外部結合 |
2.2.2 比較演算子 ^=
Oracle 独自の比較演算子 ^= は、 PostgreSQL では標準 SQL の <> に置換する。
比較演算子の置換例
| Oracle | PostgreSQL |
|---|---|
|
SELECT * FROM staff WHERE name ^= 'Kevin'; |
SELECT * FROM staff WHERE name <> 'Kevin'; |
2.2.3 POSIX 正規表現マッチ演算子
Oracle では、 POSIX 正規表現に準拠した REGEXP_LIKE 関数を用いて文字列マッチングを行う。 PostgreSQL 14 以前では POSIX 正規表現マッチ演算子か 標準 SQL の (NOT) SIMILAR TO 句に置換する。なお、 PostgreSQL 15 以降は REGEXP_LIKE 関数が用意されている。
POSIX 正規表現マッチ演算子
| 項目 | Oracle | PostgreSQL |
|---|---|---|
| ~ | 正規表現に一致(大文字小文字の区別あり) | 'tohmas' ~ '.*thomas.*' |
| ~* | 正規表現に一致(大文字小文字の区別なし) | 'tohmas' ~* '.*Thomas.*' |
| !~ | 正規表現に一致しない(大文字小文字の区別あり) | 'thomas' !~ '.*Thomas.*' |
| !~* | 正規表現に一致しない(大文字小文字の区別なし) | 'thomas' !~* '.*vadim.*' |
'p' で始まるか、'e' を2個含む名前の検索例
| Oracle | PostgreSQL |
|---|---|
|
SELECT * FROM staff WHERE REGEXP_LIKE(LOWER(name), '^p|(e.*){2}'); |
-- POSIX 正規表現マッチ演算子 SELECT * FROM staff WHERE name ~* '^p|(e.*){2}'; -- SIMILAR TO 句 |
2.3 SQL 関数
2.3.1 SQL 関数の互換性について
Oracle と互換性のある PostgreSQL のSQL 関数も存在するが、出力書式や情報精度が異なる場合があるので注意を要する。互換性がないものについては同等の機能を有するユーザー定義ファンクションを作成して対応する。以下に代表的な SQL 関数の置換例を示す。その他の SQL 関数の対応(Oracle 11g ベース)については後述の「付録 SQL 関数の対応表」を参照のこと。
DECODE 関数から CASE 式への置換例
| Oracle | PostgreSQL |
|---|---|
|
SELECT last_name, DECODE(license, 1, 'LinuC1', 2, 'LinuC2', 3, 'LinuC3', 'none') FROM employees_level; |
SELECT last_name, CASE license WHEN 1 THEN 'LinuC1' WHEN 2 THEN 'LinuC2' WHEN 3 THEN 'LinuC3' ELSE 'none' FROM employees_level; |
NVL 関数から coalesce 関数への置換例
| Oracle | PostgreSQL |
|---|---|
|
SELECT last_name, NVL(license, 'none') FROM employees_level; |
SELECT last_name, coalesce(license, 'none') FROM employees_level; |
substr 関数の第二引数に負数を指定する場合は注意が必要
| Oracle Database | PostgreSQL |
|---|---|
|
SELECT SUBSTR('ABCDEFG', -5, 4) "Substring" FROM DUAL; Substring --------- CDEF |
SELECT substr('ABCDEFG', -5, 4) "Substring"; Substring --------- |
SUBSTR 関数は PostgreSQL に移行できる。ただし、第二引数に負数が指定された場合、 Oracle では文字列の後ろから開始位置をカウントする点に注意する。
INSTR 関数から strpos 関数への置換例
| Oracle | PostgreSQL |
|---|---|
|
SELECT INSTR('ABCDEFG', 'B') "Instring" FROM DUAL; Instring -------- 2 |
SELECT strpos('ABCDEFG', 'B') "Strpos"; Strpos ------ 2 |
ADD_MONTHS 関数から算術演算子への置換例
| Oracle | PostgreSQL |
|---|---|
|
SELECT ADD_MONTHS('2022/1/1', 1) FROM DUAL; ADD_MONT -------- 22-02-01 |
SELECT date '2022-01-01' + interval '1 months'; ?coloum? ------------------- 2022-02-01 00:00:00 |
なお、PostgreSQL 16 以降は date_add 関数(加算)と date_subtract 関数(減算)が用意されている。
2.3.2 現在日時の取得と情報の精度
Oracle と PostgreSQL では、現在日時を取得するための SQL 関数に違いがある。出力される情報の精度に応じて適切な SQL 関数に置換し、必要なら to_char 関数などで加工する。なお、 PostgreSQL の current_date 関数と current_timestamp 関数は、トランザクションの開始日時を常に返す仕様のため、 SYSDATE 関数の代替として実時間を取得したい場合には clock_timestamp 関数に置換する。
現在日時の取得関数
| 項目 | Oracle | PostgreSQL |
|---|---|---|
| CURRENT_DATE | 2022-01-01 10:10:30 | 2022-01-01 |
| CURRENT_TIMESTAMP | 2022-01-01 10:10:30.281000 +9:00 | 2022-01-01 10:10:30.281000+09 |
| SYSDATE | 2022-01-01 10:10:30 | - |
| SYSTIMESTAMP | 2022-01-01 10:10:30.281000 +9:00 | - |
| clock_timestamp | - | 2022-01-01 10:10:30 |
TO_DATE 関数から to_timestamp 関数への置換例
| Oracle | PostgreSQL |
|---|---|
|
INSERT INTO emp (empno, hiredate) VALUES (1, TO_DATE('2022/01/01 09:00:00', 'YYYY/MM/DD HH24:MI:SS')); SELECT empno, TO_CHAR(hiredate, 'YYYY/MM/DD HH24:MI:SS') AS HIREDATE |
INSERT INTO emp (empno, hiredate) VALUES (1, to_timestamp('2022/01/01 09:00:00', 'YYYY/MM/DD HH24:MI:SS')); SELECT empno, to_char(hiredate, 'YYYY/MM/DD HH24:MI:SS') AS HIREDATE |
PostgreSQL の to_date 関数は時刻情報を切り捨てることに注意する。時刻情報が必要な場合、 to_timestamp 関数に置換する。
2.3.3 数値型における端数の丸め仕様
Oracle と PostgreSQL では、数値型における端数の丸め仕様が一部で異なる。Oracle では算術型(四捨五入)であるのに対し、PostgreSQL の real 型や double precision 型では、銀行型(偶数丸め)となる。銀行型は、その値に最も近い偶数に丸める仕様であり、JIS 規格に定められている(JIS Z8401-1999)。たとえば 1.5 という値は、算術型、銀行型ともに 2 に丸められるが、2.5 という値は算術型では 3 に、銀行型では最も近い偶数として 2 に丸められる。
引数の違いによる ROUND 関数の丸め仕様
| 項目 | Oracle | PostgreSQL |
|---|---|---|
| ROUND(数値型, [位置]) | 算術型(四捨五入) | 算術型(四捨五入) |
| ROUND(浮動小数点型, [位置]) | 算術型(四捨五入) | 銀行型(偶数丸め) |
PostgreSQL における ROUND 関数の実行例
|
-- numeric 型では算術型(四捨五入) SELECT round(2.5::numeric); 3 -- double precision 型では銀行型(偶数丸め) 2 |
2.4 内部仕様の違いによる主な注意事項
2.4.1 空文字列、 NULL 値、全角スペースの扱い
Oracle では 空文字列と NULL 値は同値として扱われるが、 PostgreSQL では区別される。そのため、 PostgreSQL で NULL 値を空文字列とみなす必要がある場合には、 nullif 関数を用いて変換する。また、 Oracle と PostgreSQL では全角スペースの扱いが異なるため、 SQL の整形などで全角スペースを用いている場合、構文エラーや意図した結果にならないことがある。
空文字列と NULL 値、全角スペースの対応
| 項目 | Oracle | PostgreSQL |
|---|---|---|
| 空文字列と NULL 値の扱い | 同値とみなす | 区別する |
| 空文字列を挿入した結果 | NULL 値を挿入 | 空文字列を挿入 |
|
NULL 値を含む文字列の演算結果 ⬇︎ 'ABC' || (NULL) || 'XYZ' |
NULL 値を無視 ⬇︎ 'ABCXYZ' |
NULL 値となる ⬇︎ (NULL) |
| 全角スペースの扱い | 半角スペースとみなす | 全角スペース(文字) |
nullif 関数の例
| SELECT * FROM staff WHERE nullif(name, '') IS NOT NULL; |
2.4.2 SQL 内の除算
PostgreSQL では乗除算は前方より順に実行される。割り切れない除算がある場合、数値型の精度に応じて丸められるため、Oracle とは異なる結果になる。PostgreSQL では SQL 内の除算をせず、アプリケーション側で計算した結果を格納するように処理を変更する。(float 型への CAST はアンチパターン)
計算結果の違い(例:1÷3×3)
| Oracle | PostgreSQL |
|---|---|
|
SELECT 1/3*3 AS Result FROM DUAL;
Result |
SELECT 1/3*3 AS Result;
Result |
float 型における丸め誤差の問題(ラウンディング・エラー)
|
-- 検証用の表とデータの準備 CREATE TABLE float_test (n numeric(9, 3), r real, d double precision, f float); INSERT INTO float_test VALUES (59.95, 59.95, 59.95); -- 各列の値を3倍した計算結果の違いを表示(numeric 型の結果のみ正確) |
float 型は実数を2進数形式でエンコードするため(IEEE 754 標準)、10進数で記述できるすべての数値を2進数として格納できるわけではなく、浮動小数点における一部の数値は近似値に丸められる。実質上、 float 型や real 型、 double precision 型などを使用すると完全に正確な値は期待できない。そのため、正確な10進数の数値が必要な場合は numeric 型を使用することが解決策となる。 float 型は科学技術計算に代表されるようなアプリケーションにおいて概数として扱われる用途に適するものであり、たとえば金融系のアプリケーションにおける複利計算のような用途に用いることは(CAST を含めて)アンチパターンとされている。
2.4.3 階層問い合わせにおける「深さ優先探索」
Oracle 独自の階層問い合わせは、「深さ優先探索」でデータを取り出すのに対し、PostgreSQL では「幅優先探索」となる。PostgreSQL で「深さ優先探索」とするには、contrib の tablefunc モジュールをデータベースにインストールし、connectby ファンクションを利用する。
staff 表と階層構造
| staff 表 | 階層構造 | ||
|---|---|---|---|
| id | name | manager_id | |
| 1 | John | 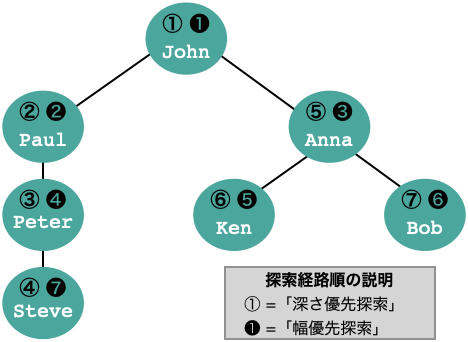 |
|
| 2 | Paul | 1 | |
| 3 | Anna | 1 | |
| 4 | Peter | 2 | |
| 5 | Steve | 4 | |
| 6 | Ken | 3 | |
| 7 | Bob | 3 | |
staff 表に対する階層問い合わせの例(「深さ優先探索」)
| Oracle | PostgreSQL |
|---|---|
|
SELECT name FROM staff START WITH name = 'John' CONNECT BY manager_id = PRIOR id; |
SELECT name FROM connectby('staff', 'id', 'manager_id', 'id', '1', 0) AS t (id int, manager_id int, level int, pos int) JOIN staff ON staff.id = t.id ORDER BY pos; |
2.4.4 トランザクション
Oracle と PostgreSQL では、トランザクションの処理において違いがあるため注意する。なお、Oracle JDBC と同様、PostgreSQL JDBC でも自動コミットを無効化することを推奨する。トランザクション中にエラーが発生した場合は最初から処理を再実行するものとし、セーブポイント機能はアプリケーションでは利用せず、手動操作などの例外的な利用にとどめるものとする。
トランザクションに関する内部動作の違い
| 項目 | Oracle | PostgreSQL |
|---|---|---|
| トランザクションの開始 | SQL 文の実行時 | START TRANSACTION 文、 または BIGIN 文の実行時 |
| トランザクションの終了 | COMMIT 文、ROLLBACK 文、 DDL 文の実行時 |
COMMIT 文または END 文、 ROLLBACK 文または ABORT 文の実行時 |
| DDL 文のロールバック | 不可 | 可 |
| トランザクション中に エラーがある場合に COMMIT 文を発行 | 成功した処理のみをコミットし、 失敗した処理は無視する。 |
トランザクション全体を失敗とみなし、 自動的に ROLLBACK 文を発行する。 また、エラーを無視して処理を 継続することはできない。 |
PostgreSQL JDBC における自動コミットの無効化例
| db.setAutoCommit(false); |
PostgreSQL は明示的にトランザクションを開始していない限り、デフォルトで自動コミットが有効である点に注意する。
2.4.5 トランザクション分離レベル
Oracle と PostgreSQL のトランザクションの分離レベルのデフォルトは、ともに READ COMMITTED であるが仕様が異なる。そのため、トランザクションが正常に終了した場合であっても実行結果に差異が生じることもあるので注意が必要である。
トランザクションの実行結果に差異が生じる例
| 時系列 | Oracle Database | PostgreSQL | ||
|---|---|---|---|---|
| トランザクション1 | トランザクション2 | トランザクション1 | トランザクション2 | |
| 1 |
SELECT * FROM t; COL1 COL2 ---- ---- 1 1 2 1 3 2 4 2 5 3 5行が選択されました。 |
SELECT * FROM t; COL1 COL2 ---- ---- 1 1 2 1 3 2 4 2 5 3 5行が選択されました。 |
SELECT * FROM t; col1 | col2 -----+----- 1 | 1 2 | 1 3 | 2 4 | 2 5 | 3 (5行) |
SELECT * FROM t; col1 | col2 -----+----- 1 | 1 2 | 1 3 | 2 4 | 2 -------------- | 5 | 3 | -------------- (5行) |
| 2 |
UPDATE t SET col2 = col2 + 1; 5行が更新されました。 |
BIGIN;
UPDATE t SET |
||
| 3 | この時点 --------> トランザクション1の更新によるロックの解放待ち |
DELETE FROM t WHERE col2 = 3; |
この時点 --------> (トランザクション2の時系列1において赤枠で囲った DELETE 対象行の判定を実施) |
BEGIN;
DELETE FROM t |
| 4 |
COMMIT; コミットが完了しました。 |
COMMIT; COMMIT |
||
| 5 | この時点 --------> トランザクション1のロックが解放され、時系列3の SQL を時系列2の結果に対して実行(DELETE 対象行の判定を実施) |
2行が削除されました。
COMIT; |
この時点 --------> (時系列3で判定した DELETE 対象行に対して WHERE 句の再判定を実施)時系列2の結果を受けて0行 |
DELETE 0
COMMIT; |
| 6 |
SELECT * FROM t; COL1 COL2 ---- ---- 1 2 2 2 5 4 3行が選択されました。 |
SELECT * FROM t; COL1 COL2 ---- ---- 1 2 2 2 5 4 3行が選択されました。 |
SELECT * FROM t; col1 | col2 -----+----- 1 | 2 2 | 2 3 | 3 4 | 3 5 | 4 (5行) |
SELECT * FROM t; col1 | col2 -----+----- 1 | 2 2 | 2 3 | 3 4 | 3 5 | 4 (5行) |
なお、 PostgreSQL のトランザクション2にて、時系列3で『BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ』を指定すると、時系列5ではエラーとなる。(ERROR: could not serialize access due to concurrent update)
第3章 手続き型言語とストアド・オブジェクトの移行
3.1 PL/SQL から PL/pgSQL への移行
3.1.1 PL/pgSQL について
PL/pgSQL は、SQL に制御構造(繰り返し処理や条件分岐など)を組み込んだ手続き型言語である。 PostgreSQL に標準実装されており、 Oracle の PL/SQL に相当する。記述された処理ロジックはユーザー定義ファンクションとしてデータベースに格納することができるが、事前にコンパイルはされておらず、実行時に解釈される。
3.1.2 基本構造とコメント
Oracle と PostgreSQL とで基本構造やコメントの基本的な構文に違いはない。
基本構造
|
DECLARE 変数名 データ型; BIGIN 処理; END; |
コメント
|
<行末までをコメントとして扱う場合> -- コメント <コメント・ブロックを設ける場合> |
3.1.3 データ型と変数
PostgreSQL のデータ型は PL/pgSQL で利用できる。同様に、 %ROWTYPE 型や %TYPE 型は、そのまま利用できる。ただし、 Oracle と PostgreSQL とで RECORD 型については注意が必要である。また、プログラム内で使用する変数は必ず DECLARE 部に記述する必要がある。(FOR 命令で使用するループ変数は除く)
RECORD 型の宣言
| Oracle | PostgreSQL |
|---|---|
|
TYPE 変数名 IS RECORD ( 変数名 データ型; ); |
変数名 RECORD; |
RECORD 型のストア例
|
-- SELECT の結果を RECORD 型にストアする場合 SELECT col1, col2 INTO rec_name FROM tbl; -- カーソル FETCH の結果を RECORD 型にストアする場合 |
PostgreSQL では RECORD 型の宣言時にレコードの内容を記述しない。レコードの内容は SELECT の結果やカーソル FETCH の結果がストアされることで定義が確定する。
3.1.4 繰り返しに関する命令
Oracle と PostgreSQL とで LOOP 命令と WHILE 命令の基本的な構文に違いはない。 FOR 命令については、 REVERSE を用いる場合に開始値と終了値の位置を入れ替える必要がある。
LOOP 命令
|
LOOP 処理; EXIT WHEN 条件式; END LOOP; |
WHILE 命令
|
WHILE 条件式 LOOP; 処理; END LOOP; |
FOR 命令
|
FOR 変数名 IN 開始値..終了値 LOOP 処理; END LOOP; |
FOR 命令で REVERSE を用いる場合
| Oracle | PostgreSQL |
|---|---|
|
FOR 変数名 IN REVERSE 1..10 LOOP 処理; END LOOP; |
FOR 変数名 IN REVERSE 10..1 LOOP 処理; END LOOP; |
3.1.5 条件分岐に関する命令
IF 命令については、 Oracle で ELSIF と記述する部分を PostgreSQL では ELSEIF に置換する。 CASE 命令については、 Oracle と PostgreSQL とで基本的な構文に違いはない。
IF 命令
| Oracle | PostgreSQL |
|---|---|
|
IF 条件式 THEN 処理; ELSIF 条件式 THEN 処理; ELSE 処理; END IF; |
IF 条件式 THEN 処理; ELSEIF 条件式 THEN 処理; ELSE 処理; END IF; |
CASE 命令
|
CASE 変数 WHEN 条件式 THEN 処理; ELSE 処理; END CASE; |
一致する WHEN 句がなく、かつ ELSE の記述がない場合には CASE_NOT_FOUND 例外が発生する。
3.1.6 その他の命令
Oracle と PostgreSQL とで EXIT 命令と CONTINUE 命令の基本的な構文に違いはない。ただし、 PostgreSQL には GOTO 命令に相当するものが存在しないため、指定したラベルに対して無条件に制御を移すことはできない。
EXIT 命令
| 構文 | 説明 |
|---|---|
| EXIT; | 最も内側の LOOP から抜ける。 |
| EXIT [ラベル名]; | 指定されたラベルの LOOP から抜ける。 |
| EXIT WHEN 条件式; | 条件式を満たすときに EXIT 命令を実行する。 |
CONTINUE 命令
| 構文 | 説明 |
|---|---|
| CONTINUE; | 実行中の LOOP の先頭に戻り、次の反復に移る。 |
| CONTINUE [ラベル名]; | 指定されたラベルの先頭に戻り、次の反復に移る。 |
| CONTINUE WHEN 条件式; | 条件式を満たすときに CONTINUE 命令を実行する。 |
GOTO 命令
| 構文 | 説明 |
|---|---|
| GOTO ラベル名; | PostgreSQL には移行できない。 |
3.1.7 カーソル
Oracle と PostgreSQL とでカーソルの宣言と終了判定の構文が異なるため適切に置換する。カーソルの OPEN や CLOSE など、その他については基本的な構文に違いはない。
カーソルの宣言
| Oracle | PostgreSQL |
|---|---|
|
CURSOR カーソル名 IS クエリ;
-- 引数を宣言する場合 |
カーソル名 CURSOR FOR クエリ;
-- 引数を宣言する場合 |
なお、 PostgreSQL において FOR が IS で記述されていてもエラーにはならない。また、引数を宣言する際に IN 句が不要である。
カーソルの宣言(refcursor)
|
CREATE OR REPLACE FUNCTION ファンクション名 () RETURNS refcursor AS $$
DECLARE BEGIN |
ファンクションの引数や戻り値、変数としてカーソルを使用する場合、 refcursor 型として宣言する。(PL/SQL の SYS_REFCURSOR に相当)
カーソルの終了判定
| Oracle | PostgreSQL |
|---|---|
| カーソル名%NOTFOUND; | NOTFOUND; |
カーソルの OPEN
| OPEN カーソル名; |
カーソルの CLOSE
| CLOSE カーソル名%; |
カーソルの FETCH
| FETCH カーソル名 INTO 変数; |
カーソルの更新
|
-- UPDATE UPDATE 表名 SET 更新内容 WHERE CURRENT OF カーソル名; -- DELETE |
3.1.8 エラー・ハンドリング
Oracle と PostgreSQL とでエラー・ハンドリングに関する基本的な構文に違いはない。ただし、例外名が異なるものは個別に置換する。なお、 Oracle では DECLARE 部で例外名を宣言して RAISE 文で呼び出せるが、 PostgreSQL では DECLARE 部で例外名を宣言できないため、 RAISE 文で例外の詳細を記述する。
EXCEPTION 文
|
EXCEPTION WHEN エラーコード1(もしくは例外名1) THEN エラー処理内容1; WHEN エラーコード2(もしくは例外名2) THEN エラー処理内容2; WHEN OTHERS THEN エラー処理内容3; END; |
RAISE 文
| RAISE 例外; |
エラー・コードとエラー・メッセージの対応
| 項目 | Oracle | PostgreSQL |
|---|---|---|
| エラー・コード | SQLCODE | SQLSTATE |
| エラー・メッセージ | SQLERRM | SQLERRM |
代表的な例外名の対応
| 項目 | Oracle | PostgreSQL |
|---|---|---|
| CASE が存在しない | CASE_NOT_FOUND | CASE_NOT_FOUND |
| 無効なカーソル状態 | INVALID_CURSOR | INVALID_CURSOR_STATE |
| データが存在しない | NO_DATA_FOUND | NO_DATA_FOUND |
| メモリが不足 | STORAGE_ERROR | OUT_OF_MEMORY |
| 行が多過ぎる | TOO_MANY_ROWS | TOO_MANY_ROWS |
| ゼロによる除算 | ZERO_DIVIDE | DIVISION_BY_ZERO |
NO_DATA_FOUND 例外のハンドリング例
|
BEGIN SELECT * INTO STRICT myrec FROM emp WHERE empname = myname; EXCEPTION WHEN NO_DATA_FOUND THEN RAISE EXCEPTION 'employee % not found' , myname; WHEN TOO_MANY_ROWS THEN RAISE EXCEPTION 'employee % not unique', myname; END; |
Oracle では SELECT の結果が0行であれば NO_DATA_FOUND 例外に該当するが、 PostgreSQL では明示的にハンドリングしなければ例外として判定されない。具体的には SELECT INTO 文に STRICT 句を指定して EXCEPTION 文で捕捉するか、代入先の変数が NULL 値であるかを確認して例外を投げる必要がある。 STRICT 句の有無に関し、以下の注意点が存在する。
- STRICT 句が指定されない場合、 SELECT の結果が0行であれば代入先の変数に NULL 値が返される。(NO_DATA_FOUND 例外は発生しない)
- STRICT 句が指定された場合、 SELECT の結果は常に1行でなければならない。(2行以上だと TOO_MANY_ROWS 例外が発生する)
3.2 ストアド・オブジェクト
3.2.1 プロシージャ
Oracle のプロシージャに相当するものが PostgreSQL にも存在するが、コンパイルはされない。それぞれの手続き型言語である PL/SQL と PL/pgSQL は基本構文が似ている反面、トランザクション制御の仕様が異なる点もあるので注意する。
プロシージャの置換例
| Oracle | PostgreSQL |
|---|---|
|
CREATE PROCEDURE p1(id IN INTEGER) IS count INTEGER; BEGIN LOCK TABLE test IN EXCLUSIVE MODE; SELECT count(*) INTO count FROM test; IF count >= 10 THEN COMMIT; raise_application_error(-20000, 'Cannot create data'); END IF; BEGIN INSERT INTO test VALUES (id); EXCEPTION WHEN dup_val_on_index THEN NULL; END; COMMIT; END; / |
CREATE PROCEDURE p1(id IN integer) AS $$ DECLARE count integer; BEGIN LOCK TABLE test IN EXCLUSIVE MODE; SELECT count(*) INTO count FROM test; IF count >= 10 THEN COMMIT; RAISE EXCEPTION 'Cannot create data'; END IF; BEGIN INSERT INTO test VALUES (id); EXCEPTION WHEN unique_violation THEN END; COMMIT; END; $$ LANGUAGE plpgsql; |
トランザクション内から COMMIT や ROLLBACK を含むプロシージャを呼び出すとエラー
|
testdb=# BEGIN; ------------> 明示的なトランザクション開始 BEGIN testdb=# CALL p1(1); ------------> p1 内で COMMIT やROLLBACK を実行 |
BEGEIN と EXCEPTION の間に COMMIT や ROLLBACK は記述できない
| 誤りの例 | 対処策 |
|---|---|
|
CREATE PROCEDURE p1() AS $$ ーーーーーーーーーーー | BEGIN | LOOP | IF 〜 THEN | 処理1; | COMMIT; ----> 記述不可 | END IF; | END LOOP; | EXCEPTION | 処理A; | COMMIT; ーーーーーーーーーーー END; $$ LANGUAGE plpgsql; |
CREATE PROCEDURE p1() AS $$ BEGIN LOOP IF 〜 THEN ーーーーーーーーーーー | BEGIN | 処理1; | EXCEPTION | 処理A; ----> サブブロック化 | COMMIT; | RETURN; | END; ーーーーーーーーーーー COMMIT; END IF; END LOOP; END; $$ LANGUAGE plpgsql; |
3.2.2 ファンクション
Oracle のファンクションに相当するものが PostgreSQL にも存在するが、コンパイルはされない。 PostgreSQL のファンクションはトランザクション制御が実行できないなど、プロシージャとの違いにも注意が必要である。
CREATE FUNCTION 構文の簡易比較
| Oracle | PostgreSQL |
|---|---|
|
CREATE OR REPLACE FUNCTION ファンクション名 (引数名 IN データ型) RETURN 戻り値データ型 IS 変数名 データ型; BEGIN |
CREATE OR REPLACE FUNCTION ファンクション名 (引数名 IN データ型) RETURNS 戻り値データ型 AS $$ DECLARE BEGIN |
ファンクションの引数に関し、以下の注意点が存在する。
- 引数に初期値を代入する場合、 Oracle では := を使用するが、 PostgreSQL では = を使用する。
- 引数の異なる同名のファンクションを作成する際、 OUT 引数は PostgreSQL によって違いとして考慮されない。(引数名や数の違いが OUT 引数によるものであれば、既存のファンクションと同名で同引数であると判断されてエラーになる)
- 引数の異なる同名のファンクションが存在する場合、 DROP 時には引数を含めて指定する必要がある。
CREATE FUNCTION 構文の対応
| 項目 | Oracle | PostgreSQL |
|---|---|---|
| 定義の開始 | IS 句 | AS 句 |
| ファンクションの戻り型の指定 | RETURN 句 | RETURNS 句 |
| 変数宣言部 | DECLARE が不要 | DECLARE が必要 |
| 引数がない場合 | 括弧が不要 func1 |
括弧が必要 func1() |
| 引数の初期値を指定 | := | = |
| 戻り型に RECORD 型を使用 | ( TABLE 関数で)使用可 | 使用可 |
| 言語の指定 | - | 必要 |
| 他言語による記述 | 不可 | 可 |
他言語( SQL )による記述例
|
-- ファンクションの作成(常に0を戻り値とする) CREATE OR REPLACE FUNCTION const_0() RETURNS int AS $$ SELECT 0; $$ LANGUAGE sql; -- ファンクションの実行 |
パイプライン・ファンクションの置換例
| Oracle | PostgreSQL |
|---|---|
|
-- 表型の作成 CREATE TYPE num_rows AS TABLE OF NUMBER; -- ファンクションの作成 BEGIN -- ファンクションの実行( TABLE 関数経由) |
-- 集合型を返すファンクションを作成 CREATE FUNCTION row_generator(rows_in integer) RETURNS SETOF INTEGER AS $$ BEGIN -- ファンクションの実行 |
PostgreSQL のプロシージャとファンクションの比較
| 項目 | プロシージャ | ファンクション | |
|---|---|---|---|
| 呼び出し方法 | CALL 文 CALL p1('test'); |
SELECT 文 SELECT f1('test'); |
|
| 引数 | IN | ○ | ○ |
| OUT | × ( PostgreSQL 13 以前) ○ ( PostgreSQL 14 以降) |
○ | |
| INOUT | ○ | ○ | |
| VARIADIC | ○ | ○ | |
| オプション | RETURNS | × ※ INOUT 引数で代替可 |
○ |
| ROWS | × | ○ | |
| PARALLEL | × | ○ | |
| CALLED ON | × | ○ | |
| トランザクション 制御 |
COMMIT | ○ | × |
| ROLLBACK | ○ | × | |
| ROLLBACK TO | × | × | |
| SAVEPOINT | × | × | |
3.2.3 パッケージ
Oracle のパッケージに相当するものが PostgreSQL に存在しないため、下記の対応をとる。
パッケージの対応
| 項目 | 説明 |
|---|---|
| パッケージ | スキーマをパッケージに見立て、ファンクション群を配置することで代替する。 |
| パッケージ定数 | パッケージ定数としたい値を戻り値とするファンクションを作成し、その戻り値を定数にセットすることで代替する。 |
| パッケージ変数 | パッケージ変数としたい値を一時表に保持することで代替する。 (一時表のスコープはセッション単位であり、他のセッションとの混用は生じない) |
スキーマによるパッケージの代替例
|
-- スキーマの作成 CREATE SCHEMA pack1; -- ファンクションの作成(1つ目) -- ファンクションの作成(2つ目) -- ファンクションの実行 |
ファンクションによるパッケージ定数の代替例
|
-- ファンクションの作成(常に0を戻り値とする) CREATE OR REPLACE FUNCTION pack1.const_0() RETURNS int AS $$ SELECT 0; $$ LANGUAGE sql; -- 定数の代入 -- 条件判定 |
凡例
互換性あり(PostgreSQL に同名の SQL 関数が存在)
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| XXX | ○ | (空欄) |
※ Oracle と挙動が異なる場合もある。
互換性あり(PostgreSQL に同等の SQL 関数が存在)
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| XXX | ○ | (置換対象の SQL 関数や式、注意事項) |
※ Oracle と同名かつ同機能のユーザー定義ファンクションを作成し、互換性を確保できる場合もある。
互換性に難あり
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| XXX | △ | (説明) |
※ 移行のハードルが高いか、完全な移行が困難なため、アプリケーションでの対応を検討する。
互換性なし
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| XXX | × |
※ アプリケーションでの対応を検討する。
SQL 関数の対応表
A
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| ABS | ○ | |
| ACOS | ○ | |
| ADD_MONTHS | ○ | 算術演算子 (参照)
16~: |
| APPENDCHILDXML | × | |
| ASCII | ○ | |
| ASCIISTR | ○ |
to_ascii
※ 次の文字コードからの変換のみをサポート |
| ASIN | ○ | |
| ATAN | ○ | |
| ATAN2 | ○ | |
| AVG | ○ |
B
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| BFILENAME | × | |
| BIN_TO_NUM | △ |
※ ユーザー定義ファンクションによる置換例
CREATE OR REPLACE FUNCTION BIN_TO_NUM(VARIADIC arr int[]) SELECT lpad(array_to_string($1, ''), 32, '0')::bit(32)::int; |
| BITAND | ○ | & 演算子 |
C
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| CARDINALITY | ○ | |
| CAST | ○ | |
| CEIL | ○ | |
| CHARTOROWID | × | |
| CHR | ○ | |
| CLUSTER_ID | × | |
| CLUSTER_PROBABILITY | × | |
| CLUSTER_SET | × | |
| COALESCE | ○ | |
| COLLECT | × | |
| COMPOSE | × | |
| CONCAT | ○ | |
| CONVERT | ○ |
※ Oracle と使用可能な文字コードに違いがある (引数に指定するキャラクタ・セットの書き換えが必要) |
| CORR | ○ | |
| CORR_* | × | |
| COS | ○ | |
| COSH | ○ | (exp(n) + exp(-n)) / 2 |
| COUNT | ○ | |
| COVAR_POP | ○ | |
| COVAR_SAMP | ○ | |
| CUBE_TABLE | × | |
| CUME_DIST | ○ | |
| CURRENT_DATE | ○ | clock_timestamp, current_timestamp (参照) |
| CURRENT_TIMESTAMP | ○ | clock_timestamp, current_timestamp (参照) |
| CV | × |
D
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| DATAOBJ_TO_PARTITION | × | |
| DBTIMEZONE | ○ |
※ pg_settings システム・カタログの参照例
SELECT reset_val FROM pg_settings |
| DECODE | ○ | CASE 式 (参照) |
| DECOMPOSE | × | |
| DELETEXML | × | |
| DENSE_RANK | ○ | |
| DEPTH | × | |
| DEREF | × | |
| DUMP | × |
E
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| EMPTY_BLOB | × | |
| EMPTY_CLOB | × | |
| EXISTNODE | × | |
| EXP | ○ | |
| EXTRACT (日時) | ○ | |
| EXTRACT (XML) | × | |
| EXTRACTVALUE | × |
F
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| FEATURE_ID | × | |
| FEATURE_SET | × | |
| FEATURE_VALUE | × | |
| FIRST | × | |
| FIRST_VALUE | ○ | |
| FLOOR | ○ | |
| FROM_TZ | ○ | timezone |
G
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| GREATEST | ○ | |
| GROUP_ID | × | |
| GROUPING | ○ | |
| GROUPING_ID | × |
H
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| HEXTORAW |
※ ユーザー定義ファンクションによる置換例 (RAW 型を bytea 型に対応づけられる場合) CREATE OR REPLACE FUNCTION HEXTORAW(text) SELECT decode($1, ‘hex’); |
I
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| INITCAP | ○ | |
| INSERTCHILDXML | × | |
| INSERTCHILDXMLAFTER | × | |
| INSERTCHILDXMLBEFORE | × | |
| INSERTXMLAFTER | × | |
| INSERTXMLBEFORE | × | |
| INSTR | ○ | strpos (参照) |
| ITERATION_NUMBER | × |
L
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| LAG | ○ | |
| LAST | × | |
| LAST_DAY | ○ | last_date |
| LAST_VALUE | ○ | |
| LEAD | ○ | |
| LEAST | ○ | |
| LENGTH | ○ | |
| LISTAGG | × | |
| LN | ○ | |
| NLNVL | ○ | |
| LOCALTIMESTAMP | ○ | |
| LOG | ○ | |
| LOWER | ○ | ※ 戻り値が text 型である点に注意 |
| LPAD | ○ | ※ マルチバイト文字を扱う場合の挙動が異なる点に注意 |
| LTRIM | ○ | ※ 戻り値が text 型である点に注意 |
M
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| MAKE_REF | × | |
| MAX | ○ | |
| MEDIAN | × | |
| MIN | ○ | |
| MOD | ○ | |
| MONTHS_BETWEEN | ○ |
N
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| NANVL | ○ | |
| NCHR | × | |
| NEW_TIME | ○ | timezone(タイムゾーン2, timezone(タイムゾーン1, 日時)) |
| NEXT_DAY | ○ | |
| NLS_CHARSET_DECL_LEN | × | |
| NLS_CHARSET_ID | × | |
| NLS_CHARSET_NAME | × | |
| NLS_INITCAP | × | |
| NLS_LOWER | × | |
| NLS_UPPER | × | |
| NLSSORT | × | |
| NTH_VALUE | ○ | |
| NTILE | ○ | |
| NULLIF | ○ | |
| NUMTODSINTERVAL | ○ | make_interval |
| NUMTOYMINTERVAL | ○ | make_interval |
| NVL | ○ | coalesce (参照) |
| NVL2 | ○ | coalesce (参照) |
O
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| ORA_DST_AFFECTED | × | |
| ORA_DST_CONVERT | × | |
| ORA_DST_ERROR | × | |
| ORA_HASH | × |
P
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| PATH | ○ | xpath, xpath_exists |
| PERCENT_RANK | ○ | |
| PERCENTILE_CONT | ○ | |
| PERCENTILE_DISC | ○ | |
| POWER | ○ | |
| POWERMULTISET | × | |
| POWERMULTISET_BY_CARDINALITY | × | |
| PREDICTION | × | |
| PREDICTION_BOUNDS | × | |
| PREDICTION_COST | × | |
| PREDICTION_DETAILS | × | |
| PREDICTION_PROBABILITY | × | |
| PREDICTION_SET | × | |
| PRESENTNNV | × | |
| PRESENTV | × | |
| PREVIOUS | × |
R
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| RANK | ○ | |
| RATIO_TO_REPORT | × | |
| RAWTOHEX | △ |
※ ユーザー定義ファンクションによる置換例 (RAW 型を bytea 型に対応づけられる場合) CREATE OR REPLACE FUNCTION RAWTOHEX(bytea) SELECT encode($1, 'hex'); |
| REF | × | |
| REFTOHEX | × | |
| REGEXP_COUNT | 15〜 ○ 〜14 |
15〜: regexp_count 〜14: |
| REGEXP_INSTR | 15〜 ○ 〜14 |
15〜: regexp_instr 〜14: |
| REGEXP_LIKE | ○ |
15〜: regexp_like (参照) 〜14: |
| REGEXP_REPLACE | ○ | |
| REGEXP_SUBSTR | ○ |
〜15: regexp_substr 〜14: |
| REGR_AVGY | ○ | |
| REGR_AVGX | ○ | |
| REGR_COUNT | ○ | |
| REGR_INTERCEPT | ○ | |
| REGR_R2 | ○ | |
| REGR_SLOPE | ○ | |
| REGR_SYY | ○ | |
| REGR_SXY | ○ | |
| REGR_SXX | ○ | |
| REMAINDER | ○ | n1 - n2 * round(n1 / n2) |
| REPLACE | ○ | |
| ROUND (数値) | ○ | |
| ROUND (日付) | ○ | |
| ROW_NUMBER | ○ | |
| ROWIDTOCHAR | × | |
| ROWIDTONCHAR | × | |
| RPAD | ○ | ※ マルチバイト文字を扱う場合の挙動が異なる点に注意 |
| RTRIM | ○ | ※ 戻り値が text 型である点に注意 |
S
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| SCN_TO_TIMESTAMP | × | |
| SESSIONTIMEZONE | ○ | current_setting(‘TimeZone’) |
| SET | × | |
| SIGN | ○ | |
| SIN | ○ | |
| SINH | ○ | (exp(n) - exp(-n)) / 2 |
| SOUNDEX | △ | ※ contrib の fuzzystrmatch 内に同名の ファンクションが存在するが、マルチバイトでは 十分に動作しない |
| SQRT | ○ | |
| STATS_BINOMIAL_TEST | × | |
| STATS_CROSSTAB | × | |
| STATS_F_TEST | × | |
| STATS_KS_TEST | × | |
| STATS_MODE | × | |
| STATS_MW_TEST | × | |
| STATS_ONE_WAY_ANOVA | × | |
| STATS_T_TEST_* | × | |
| STATS_WSR_TEST | × | |
| STDDEV | ○ | |
| STDDEV_POP | ○ | |
| STDDEV_SAMP | ○ | |
| SUBSTR | ○ | ※ 第二引数が負数の場合の挙動が異なる (参照) |
| SUM | ○ | |
| SYS_CONNECT_BY_PATH | × | |
| SYS_CONTEXT | × | |
| SYS_DBURIGEN | × | |
| SYS_EXTRACT_UTC | ○ | timezone('UTC', 日時) |
| SYS_GUID | × | |
| SYS_TYPEID | × | |
| SYS_XMLAGG | × | |
| SYS_XMLGEN | × | |
| SYSDATE | ○ | clock_timestamp (参照) |
| SYSTIMESTAMP | ○ | clock_timestamp (参照) |
T
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| TAN | ○ | |
| TANH | ○ | (exp(n) - exp(-n)) / (exp(n) + exp(-n)) |
| TIMESTAMP_TO_SCN | × | |
| TO_BINARY_DOUBLE | × | |
| TO_BINARY_FLOAT | × | |
| TO_BLOB | × | |
| TO_CHAR (文字) | × | |
| TO_CHAR (数値) | ○ | |
| TO_CHAR (日時) | ○ | |
| TO_CLOB | × | |
| TO_DATE | ○ | |
| TO_DSINTERVAL | × | |
| TO_LOB | × | |
| TO_MULTI_BYTE | × | |
| TO_NCHAR (文字) | × | |
| TO_NCHAR (数値) | × | |
| TO_NCHAR (日時) | × | |
| TO_NCLOB | × | |
| TO_NUMBER | ○ | |
| TO_SINGLE_BYTE | × | |
| TO_TIMESTAMP | ○ | |
| TO_TIMESTAMP_TZ | ○ | to_timestamp |
| TO_YMINTERVAL | × | |
| TRANSLATE | ○ | |
| TRANSLATE … USING | × | |
| TREAT | × | |
| TRIM | ○ | |
| TRUNC (数値) | ○ | |
| TRUNC (日付) | ○ | date_trunc |
| TZ_OFFSET | ○ |
※ pg_timezone_names システム・カタログの参照例
SELECT utc_offset FROM pg_timezone_names |
U
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| UID | × | |
| UNISTR | ○ | u&'xxxxx' |
| UPDATEXML | × | |
| UPPER | ○ | ※ 戻り値が text 型である点に注意 |
| USER | ○ | user, current_user |
| USERENV | × |
V
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| VALUE | × | |
| VAR_POP | ○ | |
| VAR_SAMP | ○ | |
| VARIANCE | ○ | |
| VSIZE | △ |
※ 引数型の oid から pg_type システム・カタログを 参照して算定できるが typelen が実サイズとは 限らないため datum.c の datumGetSize ファンクションで実サイズを確認 |
W
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| WIDTH_BUCKET | ○ |
X
| Oracle | 移行 | PostgreSQL |
|---|---|---|
| XMLAGG | ○ | |
| XMLCAST | × | |
| XMLCDATA | × | |
| XMLCOLATTVAL | × | |
| XMLCOMMENT | ○ | |
| XMLCONCAT | ○ | |
| XMLDIFF | × | |
| XMLELEMENT | ○ | |
| XMLEXISTS | ○ | |
| XMLFOREST | ○ | |
| XMLISVALID | × | |
| XMLPARSE | ○ | |
| XMLPATCH | × | |
| XMLPI | ○ | |
| XMLQUERY | × | |
| XMLROOT | ○ | |
| XMLSEQUENCE | × | |
| XMLSERIALIZE | ○ | |
| XMLTABLE | ○ | |
| XMLTRANSFORM | × |