-
2020-08-20 PostgreSQL
Pgpool-II+PostgreSQL12+Zabbix5.0の組み合わせ構築
はじめに
みなさん、こんにちは。インサイトの加藤です。
今回は実際にPgpool-IIを使った構築について書かせていただきます。
手順が多いため時間がかかるとは思いますが、是非最後まで読んで構築してみてください。
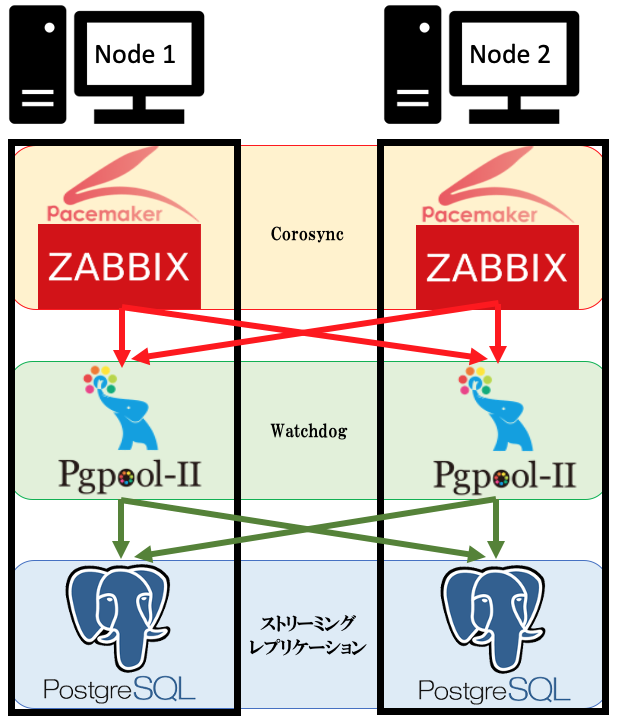
構築概要
今回の構築では2台構成とします。
冗長化箇所はZabbixとPgpool-II、PostgreSQLの3つです。
クエリ処理のフローとしては、Zabbixの操作クエリをPgpool-IIが受け取り、Pgpool-IIがPostgreSQLへクエリを振り分け、クライアントへ結果が返されます。
つまりはこの構成によってPostgreSQLの参照処理の負荷を分散しつつ、単一障害点がないという状態になるということです。
構築イメージ
バージョンについて
- OSはCentOSのバージョン7.8
- PostgreSQLのバージョンは12.3
- Zabbixのバージョンは5.0
- Pgpoolのバージョンは4.2
- Pacemakerのバージョンは1.1
大まかな構築の流れ
- PostgreSQLの構築
- Pgpool-IIの導入
- Pacemakerの導入
- Zabbixの構築
- Pacemakerのリソース設定
注意点
今回の構築では本番での運用を想定しておりません。本番での運用を検討する場合は以下の点にご注意ください。
設定値の検討
実際に運用する場合、各ソフトウェアの設定は運用時の制約等を考慮する必要があります。
セキュリティ面での考慮
実際に運用する場合、各ソフトウェアのクライアント認証方式やSELINUXなど、セキュリティ面での考慮が必要です。
1. PostgreSQLの構築
1-1.環境変数の設定 (全ノード)
# vi ~/.bash_profile
--------------------------------------------------
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
export PGHOME=/usr/pgsql-12
export PGLIB=$PGHOME/lib
export PGDATA=$PGHOME/data
PATH=$PATH:HOME/bin:$PGHOME/bin
export PATH
--------------------------------------------------
# source ~/.bash_profile1-2.postgresユーザーとディレクトリの作成 (全ノード)
# useradd -m postgres -p postgres
# mkdir -p $PGDATA
# mkdir $PGLIB
# mkdir $PGHOME/arclog
# chown -R postgres:postgres $PGHOME
# chmod -R 700 $PGHOME1-3.PostgreSQLのインストール (全ノード)
# yum -y install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
# yum -y install postgresql12 postgresql12-server1-4.PostgreSQLデータベースクラスタの初期化 (主系のみ)
# su postgres && cd
$ initdb1-5.PostgreSQLの設定ファイルを編集 (主系のみ)
今回はZabbixサーバーなので性能重視とします。
$ vi $PGDATA/postgresql.conf
----------------------------------------------------------------------------------------------------
listen_addresses = '*'
hot_standby = on
wal_level = replica
wal_log_hints = on
synchronous_commit = local
max_wal_senders = 4 #最大何台にwalを送るか
max_replication_slots = 10 #最大何台スタンバイを設定するか
archive_mode = on
archive_command = '/bin/cp %p /usr/pgsql-12/arclog/%f'
lc_messages = 'en_US'
----------------------------------------------------------------------------------------------------$ vi $PGDATA/pg_hba.conf
---------------------------------------------------------------------------------------------------------------
host replication all 192.168.56.105/32 trust #レプリケーション用 <(追記)
host replication all 192.168.56.106/32 trust #レプリケーション用 <(追記)
host all all 192.168.56.105/32 trust #接続用 <(追記)
host all all 192.168.56.106/32 trust #接続用 <(追記)
host all all 192.168.56.150/32 trust #Pgpool-II用仮想IP <(追記)
host all all 192.168.249.49/32 trust #Zabbix用仮想IP <(追記)
---------------------------------------------------------------------------------------------------------------
$ pg_ctl start2. Pgpool-II構築
2-1.Pgpool-IIのインストール (全ノード)
$ exit
# yum -y install https://www.pgpool.net/yum/rpms/4.1/redhat/rhel-7-x86_64/pgpool-II-release-4.1-2.noarch.rpm
# yum -y install pgpool-II-pg12-extensions2-2.Pgpool-IIの設定ファイルを編集 (全ノード)
PostgreSQL用IPはeth1の192.168.56.XXXとします。
vi /etc/pgpool-II/pgpool.conf
-----------------------------------------------------------------------------------------------------
listen_addresses = '*'
backend_hostname0 = 'node1' #小文字ホスト名で設定する必要あり
backend_data_directory0 = '/usr/pgsql-12/data'
backend_application_name0 = 'node1'
backend_hostname1 = 'node2' #小文字ホスト名で設定する必要あり
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/usr/pgsql-12/data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_application_name1 = 'node2'
enable_pool_hba = on
num_init_children = 32 #最大同時接続数
max_pool = 4 #コネクションの最大数
child_life_time = 0
insert_lock = on
load_balance_mode = on
database_redirect_preference_list = 'zabbix:standby(0.9)' #Standbyサーバーに参照クエリの9割を渡す
statement_level_load_balance = on
master_slave_mode = on
sr_check_period = 10
sr_check_user = 'postgres'
health_check_period = 10
health_check_user = 'postgres'
failover_command = '/etc/pgpool-II/failover.sh %d %h %p %D %m %H %M %P %r %R %N %S'
recovery_user = 'postgres'
recovery_1st_stage_command = 'recovery_1st_stage'
use_watchdog = on
wd_hostname = '通信元ホスト名' #小文字ホスト名で設定する必要あり
wd_port = 9002
delegate_IP = 192.168.56.150 #PostgreSQL接続用VIP
if_cmd_path = ''
if_up_cmd = '/usr/bin/sudo /sbin/ip addr add $_IP_$/24 dev eth1 label eth1:1'
if_down_cmd = '/usr/bin/sudo /sbin/ip addr del $_IP_$/24 dev eth1'
arping_path = ''
arping_cmd = '/usr/bin/sudo /usr/sbin/arping -U $_IP_$ -w 1 -I eth1'
enable_consensus_with_half_votes = on #50%の投票で可決されるようになる
wd_lifecheck_user = 'postgres'
heartbeat_destination0 = '通信先ホスト名' #小文字ホスト名で設定する必要あり
other_pgpool_hostname0 = '通信先ホスト名' #小文字ホスト名で設定する必要あり
other_pgpool_port0 = 9999
other_wd_port0 = 9002
-----------------------------------------------------------------------------------------------------2-3.Pgpool-II用ディレクトリの作成と所有者権限の変更 (全ノード)
# chown -R postgres:postgres /etc/pgpool-II
# mkdir /var/run/pgpool-II/
# chown postgres:postgres /var/run/pgpool-II/
# mkdir /var/log/pgpool
# chown postgres:postgres /var/log/pgpool2-4.レプリケーション用ホスト名の設定 (全ノード)
# vi /etc/hosts
-------------------------------
192.168.56.105 Node1
192.168.56.106 Node2
-------------------------------2-5.SELINUXを停止 (全ノード)
# vi /etc/selinux/config
--------------------------------
SELINUX=disabled <(編集)
--------------------------------2-6.sshの設定と鍵交換 (全ノード)
postgresユーザーのパスワードを「postgres」とします。
# vi /etc/ssh/sshd_config
-------------------------------------------------
PubkeyAuthentication yes <(編集)
PasswordAuthentication yes <(編集)
ChallengeResponseAuthentication yes <(編集)
-------------------------------------------------
# systemctl restart sshd
# passwd postgres
ユーザー postgres のパスワードを変更。
新しいパスワード: postgres
# su postgres
$ ssh-keygen
$ ssh-copy-id postgres@node1
$ ssh-copy-id postgres@node22-7.Pgpool-IIを使うためのセキュリティ設定 (全ノード)
$ pg_md5 -p
password: postgres
e8a48653851e28c69d0506508fb27fc5
$ vi /etc/pgpool-II/pcp.conf
-----------------------------------------
postgres:e8a48653851e28c69d0506508fb27fc5
-----------------------------------------
$ vi /etc/pgpool-II/pool_passwd
-----------------------------------------
postgres:e8a48653851e28c69d0506508fb27fc5
-----------------------------------------
$ vi ~/.pcppass
--------------------------------------
*:*:postgres:postgres
--------------------------------------
$ chmod 600 ~/.pcppass
$ vi /etc/pgpool-II/pool_hba.conf
----------------------------------------------------------------------------------
host replication all 192.168.56.105/32 trust #レプリケーション用 <(追記)
host replication all 192.168.56.106/32 trust #レプリケーション用 <(追記)
host all all 192.168.56.105/32 trust #接続用 <(追記)
host all all 192.168.56.106/32 trust #接続用 <(追記)
host all all 192.168.56.150/32 trust #PostgreSQL用仮想IP <(追記)
host all all 192.168.249.49/32 trust #Zabbix用仮想IP <(追記)
----------------------------------------------------------------------------------2-8.スクリプトの作成と配置 (全ノード)
スクリプト内の以下の変数は環境によって編集が必要です。
- PGHOME=/usr/pgsql-12
- ARCHIVEDIR=/usr/pgsql-12/arclog
- REPLUSER=postgres
サンプル : failover.sh
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
#!/bin/bash
# This script is run by failover_command.
set -o xtrace
exec > >(logger -i -p local1.info) 2>&1
# Special values:
# %d = failed node id
# %h = failed node hostname
# %p = failed node port number
# %D = failed node database cluster path
# %m = new master node id
# %H = new master node hostname
# %M = old master node id
# %P = old primary node id
# %r = new master port number
# %R = new master database cluster path
# %N = old primary node hostname
# %S = old primary node port number
# %% = '%' character
FAILED_NODE_ID="$1"
FAILED_NODE_HOST="$2"
FAILED_NODE_PORT="$3"
FAILED_NODE_PGDATA="$4"
NEW_MASTER_NODE_ID="$5"
NEW_MASTER_NODE_HOST="$6"
OLD_MASTER_NODE_ID="$7"
OLD_PRIMARY_NODE_ID="$8"
NEW_MASTER_NODE_PORT="$9"
NEW_MASTER_NODE_PGDATA="${10}"
OLD_PRIMARY_NODE_HOST="${11}"
OLD_PRIMARY_NODE_PORT="${12}"
PGHOME=/usr/pgsql-12
logger -i -p local1.info failover.sh: start: failed_node_id=$FAILED_NODE_ID old_primary_node_id=$OLD_PRIMARY_NODE_ID failed_host=$FAILED_NODE_HOST new_master_host=$NEW_MASTER_NODE_HOST
## If there's no master node anymore, skip failover.
if [ $NEW_MASTER_NODE_ID -lt 0 ]; then
logger -i -p local1.info failover.sh: All nodes are down. Skipping failover.
exit 0
fi
## Test passwrodless SSH
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ls /tmp > /dev/null
if [ $? -ne 0 ]; then
logger -i -p local1.info failover.sh: passwrodless SSH to postgres@${NEW_MASTER_NODE_HOST} failed. Please setup passwrodless SSH.
exit 1
fi
## If Standby node is down, skip failover.
if [ $FAILED_NODE_ID -ne $OLD_PRIMARY_NODE_ID ]; then
logger -i -p local1.info failover.sh: Standby node is down. Skipping failover.
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$OLD_PRIMARY_NODE_HOST -i ~/.ssh/id_rsa_pgpool "
${PGHOME}/bin/psql -p $OLD_PRIMARY_NODE_PORT -c \"SELECT pg_drop_replication_slot('${FAILED_NODE_HOST}')\"
"
if [ $? -ne 0 ]; then
logger -i -p local1.error failover.sh: drop replication slot "${FAILED_NODE_HOST}" failed
exit 1
fi
exit 0
fi
## Promote Standby node.
logger -i -p local1.info failover.sh: Primary node is down, promote standby node ${NEW_MASTER_NODE_HOST}.
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null \
postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ${PGHOME}/bin/pg_ctl -D ${NEW_MASTER_NODE_PGDATA} -w promote
if [ $? -ne 0 ]; then
logger -i -p local1.error failover.sh: new_master_host=$NEW_MASTER_NODE_HOST promote failed
exit 1
fi
logger -i -p local1.info failover.sh: end: new_master_node_id=$NEW_MASTER_NODE_ID started as the primary node
exit 0
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
$ vi /etc/pgpool-II/failover.sh
$ chmod 755 /etc/pgpool-II/failover.sh2-9.スクリプトの作成と配置 (主系のみ)
サンプル : recovery_1st_stage
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
#!/bin/bash
# This script is executed by "recovery_1st_stage" to recovery a Standby node.
set -o xtrace
exec > >(logger -i -p local1.info) 2>&1
PRIMARY_NODE_PGDATA="$1"
DEST_NODE_HOST="$2"
DEST_NODE_PGDATA="$3"
PRIMARY_NODE_PORT="$4"
DEST_NODE_ID="$5"
DEST_NODE_PORT="$6"
PRIMARY_NODE_HOST=$(hostname)
PGHOME=/usr/pgsql-12
ARCHIVEDIR=/usr/pgsql-12/arclog
REPLUSER=postgres
logger -i -p local1.info recovery_1st_stage: start: pg_basebackup for Standby node $DEST_NODE_ID
## Test passwrodless SSH
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${DEST_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ls /tmp > /dev/null
if [ $? -ne 0 ]; then
logger -i -p local1.info recovery_1st_stage: passwrodless SSH to postgres@${DEST_NODE_HOST} failed. Please setup passwrodless SSH.
exit 1
fi
## Get PostgreSQL major version
PGVERSION=${PGHOME}/bin/initdb -V | awk '{print $3}' | sed 's/\..*//' | sed 's/\([0-9]*\)[a-zA-Z].*/\1/'
if [ $PGVERSION -ge 12 ]; then
RECOVERYCONF=${DEST_NODE_PGDATA}/myrecovery.conf
else
RECOVERYCONF=${DEST_NODE_PGDATA}/recovery.conf
fi
## Create replication slot "${DEST_NODE_HOST}"
${PGHOME}/bin/psql -p ${PRIMARY_NODE_PORT} << EOQ
SELECT pg_create_physical_replication_slot('${DEST_NODE_HOST}');
EOQ
## Execute pg_basebackup to recovery Standby node
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$DEST_NODE_HOST -i ~/.ssh/id_rsa_pgpool "
set -o errexit
rm -rf $DEST_NODE_PGDATA
rm -rf $ARCHIVEDIR/*
${PGHOME}/bin/pg_basebackup -h $PRIMARY_NODE_HOST -U $REPLUSER -p $PRIMARY_NODE_PORT -D $DEST_NODE_PGDATA -X stream
if [ ${PGVERSION} -ge 12 ]; then
sed -i -e \"\\\$ainclude_if_exists = '$(echo ${RECOVERYCONF} | sed -e 's/\//\\\//g')'\" \
-e \"/^include_if_exists = '$(echo ${RECOVERYCONF} | sed -e 's/\//\\\//g')'/d\" ${DEST_NODE_PGDATA}/postgresql.conf
fi
cat > ${RECOVERYCONF} << EOT
primary_conninfo = 'host=${PRIMARY_NODE_HOST} port=${PRIMARY_NODE_PORT} user=${REPLUSER} application_name=${DEST_NODE_HOST} passfile=''/var/lib/pgsql/.pgpass'''
recovery_target_timeline = 'latest'
restore_command = 'scp ${PRIMARY_NODE_HOST}:${ARCHIVEDIR}/%f %p'
primary_slot_name = '${DEST_NODE_HOST}'
EOT
if [ ${PGVERSION} -ge 12 ]; then
touch ${DEST_NODE_PGDATA}/standby.signal
else
echo \"standby_mode = 'on'\" >> ${RECOVERYCONF}
fi
sed -i \"s/#*port = .*/port = ${DEST_NODE_PORT}/\" ${DEST_NODE_PGDATA}/postgresql.conf
"
if [ $? -ne 0 ]; then
${PGHOME}/bin/psql -p ${PRIMARY_NODE_PORT} << EOQ SELECT pg_drop_replication_slot('${DEST_NODE_HOST}'); EOQ logger -i -p local1.error recovery_1st_stage: end: pg_basebackup failed. online recovery failed exit 1 fi logger -i -p local1.info recovery_1st_stage: end: recovery_1st_stage complete exit 0 ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
サンプル : pgpool_remote_start
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
#!/bin/bash
# This script is run after recovery_1st_stage to start Standby node.
set -o xtrace
exec > >(logger -i -p local1.info) 2>&1
PGHOME=/usr/pgsql-12
DEST_NODE_HOST="$1"
DEST_NODE_PGDATA="$2"
logger -i -p local1.info pgpool_remote_start: start: remote start Standby node $DEST_NODE_HOST
## Test passwrodless SSH
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${DEST_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ls /tmp > /dev/null
if [ $? -ne 0 ]; then
logger -i -p local1.info pgpool_remote_start: passwrodless SSH to postgres@${DEST_NODE_HOST} failed. Please setup passwrodless SSH.
exit 1
fi
## Start Standby node
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$DEST_NODE_HOST -i ~/.ssh/id_rsa_pgpool "
$PGHOME/bin/pg_ctl -l /dev/null -w -D $DEST_NODE_PGDATA start
"
if [ $? -ne 0 ]; then
logger -i -p local1.error pgpool_remote_start: $DEST_NODE_HOST PostgreSQL start failed.
exit 1
fi
logger -i -p local1.info pgpool_remote_start: end: $DEST_NODE_HOST PostgreSQL started successfully.
exit 0
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
$ vi $PGDATA/recovery_1st_stage
$ vi $PGDATA/pgpool_remote_start
$ chmod 755 $PGDATA/recovery_1st_stage
$ chmod 755 $PGDATA/pgpool_remote_start2-10.Pgpool-IIを起動 (全ノード)
$ exit
# systemctl start pgpool2-11.Pgpool-IIの機能でスタンバイ側を構築 (主系のみ)
# su postgres
$ psql template1 -c "CREATE EXTENSION pgpool_recovery"
$ pcp_recovery_node -h 192.168.56.150 -p 9898 -U postgres -n 1
$ exit3. Pacemakerの導入
3-1.パッケージインストール (全ノード)
# yum -y install https://osdn.net/projects/linux-ha/downloads/70298/pacemaker-repo-1.1.19-1.1.el7.x86_64.rpm
# yum install -y pacemaker-all3-2.Corosync の設定ファイルを作成 (全ノード)
Pacemaker用IPはeth2の192.168.249.XXXとします。
# tee /etc/corosync/corosync.conf <<EOS
totem {
version: 2
cluster_name: pgzabbix
rrp_mode: passive
secauth: off
transport: udpu
token: 30000 #Corosync間の生存確認用の通信タイムアウト値
token_retransmits_before_loss_const:10 #新しい構成を形成するまでに何回トークンの再送を試みるか
join:5000 #メンバーシッププロトコルのjoinメッセージをどのくらい待つか
}
logging {
to_syslog: yes
to_logfile: yes
logfile: /var/log/cluster/corosync.log
}
nodelist {
node {
name: Node1
ring0_addr: 192.168.249.34
nodeid: 1
}
node {
name: Node2
ring0_addr: 192.168.249.35
nodeid: 2
}
}
quorum {
provider: corosync_votequorum
two_node: 1
}
EOS3-3.corosync認証鍵ファイルの設定 (主系のみ)
# corosync-keygen -l
# scp -p /etc/corosync/authkey root@node2:/etc/corosync/authkey3-4.Pacemakerを使う上でCentOSに必要なパッケージのインストール (全ノード)
# yum install -y NetworkManager-config-server
# systemctl restart NetworkManager3-5.リポジトリの追加設定 (全ノード)
CentOS同梱版のPacemakerと混在してしまわないようにリポジトリにexclude設定をbaseセクションとupdatesセクションに追記します。
# vi /etc/yum.repos.d/CentOS-Base.repo
------------------------------------------------------------------------------------------------------
[base]
exclude=pacemaker* corosync* resource-agents* crmsh* cluster-glue* libqb* fence-agents* pcs* <(追記)
[updates]
exclude=pacemaker* corosync* resource-agents* crmsh* cluster-glue* libqb* fence-agents* pcs* <(追記)
------------------------------------------------------------------------------------------------------3-6.pacemaker設定ファイルの設定 (全ノード)
Pacemakerの内部プロセスが死亡した場合にもノード故障とみなすための設定を追記します。
# vi /etc/sysconfig/pacemaker
-----------------------------
PCMK_fail_fast=yes <(追記)
-----------------------------3-7.クラスタの開始 (全ノード)
# systemctl start pacemaker4. Zabbixの構築
4-1.apacheをインストール (全ノード)
# yum -y install httpd4-2.Zabbix5.0をインストール (全ノード)
# yum -y install https://repo.zabbix.com/zabbix/5.0/rhel/7/x86_64/zabbix-release-5.0-1.el7.noarch.rpm
# yum -y install zabbix-server-pgsql zabbix-agent4-3.PostgreSQLにZabbixユーザーの作成 (主系のみ)
zabbixユーザーのパスワードを「zabbix」とします。
# sudo -u postgres createuser --pwprompt zabbix
新しいロールのためのパスワード: zabbix4-4.Zabbixのフロントエンドをインストール (全ノード)
# yum -y install centos-release-scl
# vi /etc/yum.repos.d/zabbix.repo
---------------------------------------
[zabbix-frontend]
enabled=1 <(編集)
---------------------------------------
# yum -y install zabbix-web-pgsql-scl zabbix-apache-conf-scl4-5.PostgreSQLにZabbixのデータベースを作成 (主系のみ)
# sudo -u postgres createdb -O zabbix zabbix
# zcat /usr/share/doc/zabbix-server-pgsql*/create.sql.gz | psql -U zabbix zabbix4-6.zabbix関連の設定ファイルを編集 (全ノード)
# vi /etc/zabbix/zabbix_server.conf
-------------------------------------------
SourceIP=192.168.249.49 <(編集)
DBHost=192.168.56.150 <(編集)
DBPassword=zabbix <(編集)
DBPort=9999 <(編集)
-------------------------------------------
# vi /etc/opt/rh/rh-php72/php-fpm.d/zabbix.conf
--------------------------------------------
php_value date.timezone Asia/Tokyo <(編集)
--------------------------------------------
# vi /etc/zabbix/zabbix_agentd.conf
----------------------------------------
Server=192.168.249.49 <(編集)
ServerActive=192.168.249.49 <(編集)
Hostname=自分のホスト名 <(編集)
----------------------------------------5. Pacemakerのリソース設定
5-1.リソースを記述したファイルの作成と適用 (主系のみ)
サンプル : cib_pgpool.txt
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
### Cluster Option ###
property \
no-quorum-policy="ignore" \
stonith-enabled="false" \
startup-fencing="false" \
pe-error-series-max="100" \
pe-input-series-max="100" \
pe-warn-series-max="100"
### Resource Defaults ###
rsc_defaults resource-stickiness="INFINITY" \
migration-threshold="2"
### Primitive Configuration ###
primitive VIP ocf:heartbeat:IPaddr2 \
params ip="192.168.249.49" nic="eth2" cidr_netmask="24" \
op monitor interval="30" timeout="30"
primitive ZabSrv systemd:zabbix-server \
op monitor interval=60s timeout=200s \
op start interval=0s timeout=200s
primitive HTTPD ocf:heartbeat:apache \
params configfile=/etc/httpd/conf/httpd.conf statusurl="http://192.168.249.49/server-status" \
op monitor interval=60s timeout=100s \
op start interval=0s timeout=100s
primitive rh-php systemd:rh-php72-php-fpm \
op monitor interval=60s timeout=200s \
op start interval=0s timeout=200s
### Group Configuration ###
group GRPZABBIX \
VIP \
HTTPD \
rh-php \
ZabSrv
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# vi cib_pgpool.txt
# crm configure load update cib_pgpool.txt5-2.zabbix-agentを起動 (全ノード)
# systemctl start zabbix-agent
# systemctl enable zabbix-agent5-3.WEB上の「http://192.168.249.49/zabbix」から設定
Database host : 192.168.56.150
Database post : 9999
User : zabbix
Password : zabbix
Host : 192.168.249.49
Zabbix server name : PGZABBIX
5-4.ZabbixのWeb設定を副系にも同じく設定 (主系のみ)
# scp /etc/zabbix/web/zabbix.conf.php root@node2:/etc/zabbix/web/5-5.SSHを鍵認証のみに設定 (全ノード)
# vi /etc/ssh/sshd_config
-------------------------------------------------
PasswordAuthentication no <(編集)
ChallengeResponseAuthentication no <(編集)
-------------------------------------------------
# systemctl restart sshd5-6.Zabbixの日本語文字表記パッケージをインストール (全ノード)
これで最後です!
# yum -y install zabbix-web-japaneseまとめ
とても長い時間お付き合いいただきありがとうございました。
実際に動かしてもらうとお分かりいただけるとは思いますが、フェールオーバーや、データの冗長化などうまく動作できている事が確認できるかと思います。
ただ、各パッケージのバージョンや環境によっては、同じ構築ができない可能性があることをご注意ください。
次回の内容は考えていないので、少し時間が空くことがあるとは思いますが、気長にお待ちいただけると嬉しく思っております。
今後もどうぞよろしくお願いいたします。
参考
https://www.zabbix.com/jp/
http://linux-ha.osdn.jp/wp/archives/4802
https://www.pgpool.net/docs/latest/ja/html/example-cluster.html
https://blog.drbd.jp/2015/05/corosync-conf-5/